Introduction à R
2025-08-24
Les logiciels d’analyse de données
![]()
![]()
![]()
![]()
![]()
Pourquoi R?
![]()
Open source
- Gratuit
- Collaboratif
- Communauté active
- Stackoverflow
- r-bloggers
- Adapté aux besoins des utilisateurs
Pourquoi R?
![]()
Packages
- Offre une extension des fonctionnalités de base presque infinie
- Peux répondre à des besoins très spécifiques
- 21,744 packages sur CRAN (Comprehensive R Archive Network)
- Principal dépôt où sont hébergés les packages R
- Beaucoup plus sur GitHub
- En plus de CRAN, de nombreux chercheurs publient leurs packages sur GitHub, une plateforme de partage de code
Pourquoi R?
![]()
Reproductibilité
- Rendre les analyses reproductibles
- Permet de partager les analyses
- Les scripts R permettent de partager facilement le travail
- Permet de retracer les erreurs
- Partager le code
- Encourage la transparence et la collaboration dans la recherche
Pourquoi R?
![]()
Très utilisé en science sociale
- Beaucoup de ressources
- Les LLM (comme ChatGPT) sont très performants pour R
- Beaucoup de tutoriels orientés vers les sciences sociales
- Datacamp
- Swirl
- Codeacademy
Bref… important d’utiliser les mêmes outils que les chercheurs dans votre domaine
Concept important : Le chemin d’arborescence
- Votre R est toujours ouvert dans un dossier, et donc vous devez savoir où il est pour pouvoir importer des données
- La fonction
getwd()dans R permet de savoir où vous êtes - À tout moment vous devez savoir où vous êtes dans votre ordinateur pour pouvoir importer des données, exporter des graphiques ou mettre des fichiers en relation
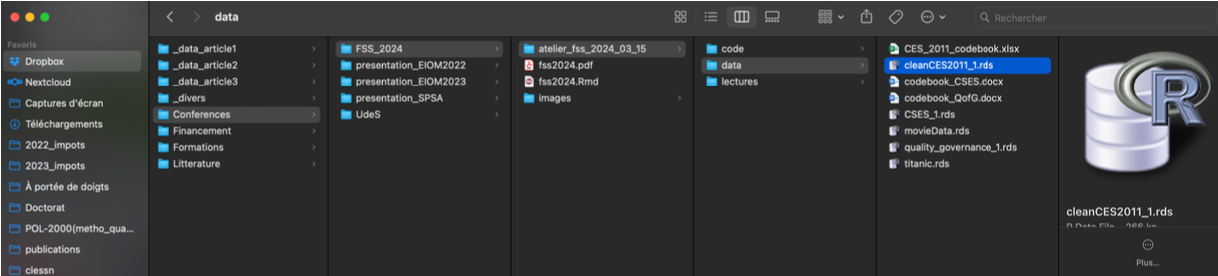
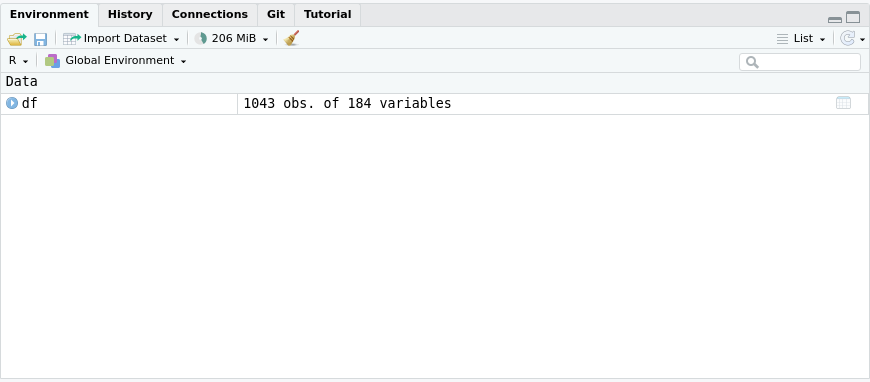
~/Dropbox/Conferences/FSS_2024/atelier_fss_2024_03_15/data/cleanCES2011_1.rds
Importer des données
Autres fonctions pour importer des données dépendamment du format:
df <- readxl::read_excel("chemin/vers/data.xlsx")df <- readRDS("chemin/vers/data.rds")